
8·
5 days agoYeah that sounds like a good idea so you can see how connected local communities are. Probably makes more sense to use original dimensions so no extra information is lost.
Other accounts:
All of my comments are licensed under the following license
Yeah that sounds like a good idea so you can see how connected local communities are. Probably makes more sense to use original dimensions so no extra information is lost.
Total communities: 2986
Total users: 21934
So the dimensions were reduced from (2986, 21934) to (2986, 2)
Edit: Also yeah it is using Umap for the algorithm and it does do something pretty similar to what you described.
I was somehow able to get both a picture and url added and it looks much better. Thx.
Either the people in [email protected] are pretty horny or its an artifact of the dimensionality reduction and means nothing.
Edit: Actually it could also be that it just didn’t collect enough data on that community and the most recent person was also active in nsfw communities. I was only able to get back 14ish days in the data for lemmy.world. They produce way to many comments and I got kicked out early.
Yeah pretty much. I wanted to see communities that had similar people that commented because I thought that would be a good way to see if there were similar kinds of discussions were happening in those communities.
For example most of the red dots to the top right are nsfw communities and it was able to clump like that because the people that comment in those communities tend to comment in the other nsfw communities as well.
edit: left -> right
I didn’t measure activity for this map. Each dot represents a community. I only used the communities that were on the top 35 instances (except lemmings.world which it couldn’t grab any comments for.)
Well I used dimensionality reduction to make it 2D so the axes are how the algorithm chose to compress it.
The original data had each data point as a community and the features as a frequency of a user posting in that community.
I know I was talking about how the map I linked to worked which is based on reddit.
Good communities, insightful posts, etc.
People say they have problems with discoverability. A map will help people find the content they want faster.
The map up above checks how similar two subreddits are by checking how much overlap the people that comment in both communities there is. It could be the same as that or maybe something different.
The easiest would be to have countries similar to how it had in the map of reddit be the instances and show the connections between subscribers maybe.
I never said we shouldn’t use algorithms I just think what those algorithms were doing could be different.

Oh I didn’t see that before. Ok I find the joke funny.
But enjoy your antifa money 🤣🤣🤣
You know you are on an anarchist instance right?
Hey I’m sorta curious, do you have any insight on what the protesters plan on doing next? Especially with the army declaring an interim government and all that.
Like is there some plan on how to make sure the movement doesn’t die down or get co-opted like other movements have?
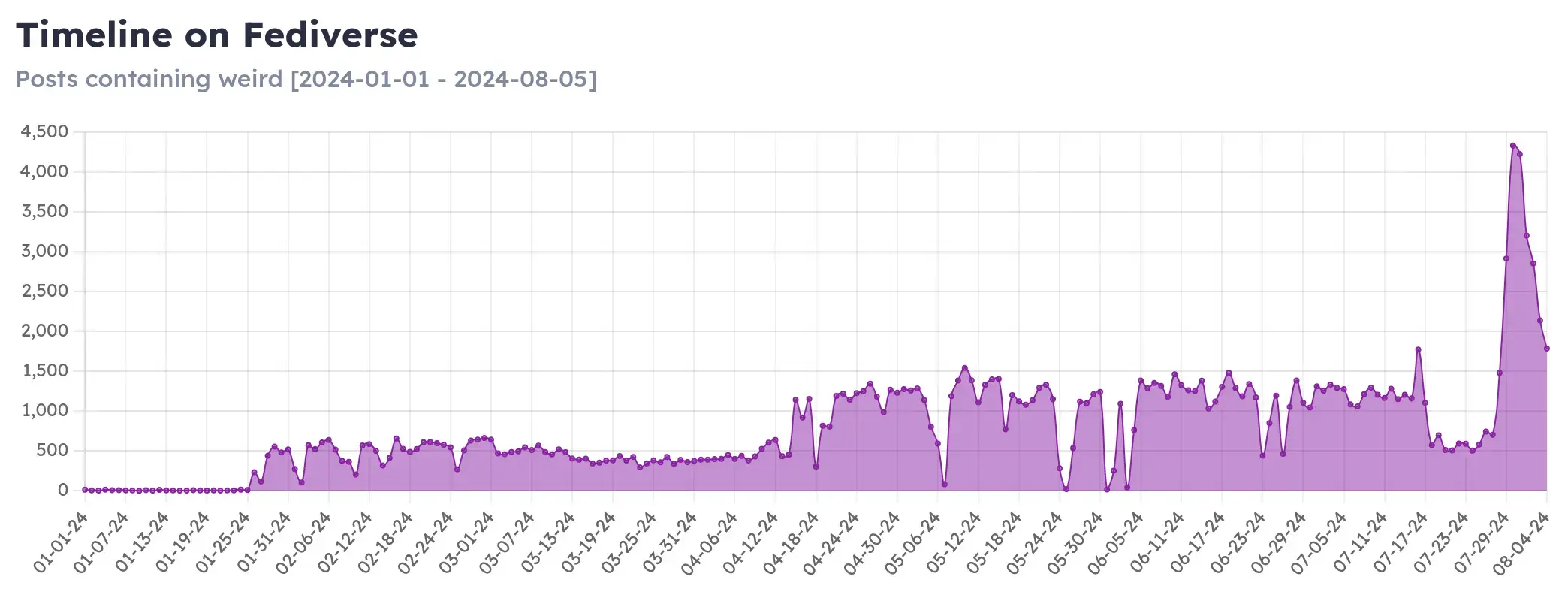
As an example below you can see a spike in the usage of the word “weird” recently that probably is related to how people are now calling republicans weird.
Well on firefox/chrome extensions you can search for text expander and choose an extension that works for you.
Or if you are using a phone you can do the same on the app store and I think there should be a few options.
Once you download one of them it should give instructions on how to use it, but in general it asks you to create a phrase that you want to be automatically triggered and a shorter phrase that automatically replaced with the longer phrase.
For example-
long phrase: The quick brown fox jumped over the moon.
short phrase: /qfox
and every time you typed /qfox it would replace it with “The quick brown fox jumped over the moon.”








I had to try scraping the websites multiple times because of stupid bugs I put in the code beforehand, so I might of put more strain on the instances than I meant too. If I did this again it would hopefully be much less tolling on the servers.
As for the cost of scraping it actually isn’t that hard I just had it running in the background most of the time.
Anti Commercial-AI license (CC BY-NC-SA 4.0)